「囲碁をディープラーニングするのは面白い」という噂なので(笑)、私も試しに一度やってみることにしました。作るならやっぱり評価関数。それも、その時の形勢を「目数」で教えてくれるやつがなんかいいですよね? とりあえず今回は19路盤用です。
まずは学習に使うデータについてです。とりあえず評価する局面は、COSUMIで打たれた19路盤互先の作り碁の棋譜から作りました。GNU Go、強い人、弱い人、意図した序盤早々の連続パス、意図しないクリックミスの混ぜ合わさった様々なよく分からない局面が出現しそうで、まあ良いのではないかと…(笑) まず、最後のパスパスを取り除き、1手から最終手の間の一様乱数にまで棋譜の手数を短くして、さらに対称形を考慮しない完全な重複分を取り除き、残った棋譜の最終局面を使うことにしました。
そして次に、その局面に付けるラベル、今回の場合は「目数単位の形勢判断」ですが、うーん、これが本当にどうするのが良いのか… とりあえず、今回の作成方法は以下のとおりです。
- まず先ほど作った局面を、コミ6目でRayの2k playoutに考えさせます
- 返ってきたwin rateが0.5に近づく方向にコミを10目ずらして、もう一度Rayに考えさせます
- それをwin rateが0.5の反対側に行くまで、繰り返します
- 0.5をまたいだ2点を結んで、0.5と交わるところを「大体の形勢」とします
- 再度、コミを「大体の形勢」として、今度はRayの20k playoutに考えさせます
- 返ってきたwin rateが0.5に近づく方向に、今度はコミを4目ずらして、もう一度Rayに考えさせます
- 先ほどと同じように、それをwin rateが0.5の反対側に行くまで、繰り返します
- 先ほどと同じように、0.5をまたいだ2点を結んで、0.5と交わるところを「最終的な形勢」とします
あまりにも素朴すぎる気はしますが、こんな感じで作りました。前半は消費リソースを減らすためにやっているだけなので、後半だけを行っても当然似たようなラベルができるはずです。
最初のころは、これを10,000局面分作っていろいろ試していたのですが、ちょっと遊んでみたいだけとはいえ、それではあまりにも少なすぎたので、50,000局面分まで増やしました。そしてそれを対称形に8倍して、ここでもう一度重複分を除去し、きりの良い数字にまで少し減らして399,000局面分できました。今回は、その内80%の319,200局面分を学習用に、残りの20%の79,800局面分を検証用に使用します。
ここまで、学習データは用意できましたので、次に実際に学習を始めます。
今回の実行環境は、
- Amazon EC2 p2.xlarge
- Ubuntu 16.04 LTS
- CUDA 8.0
- cuDNN 5.1
です。最初、手元のGPUなしのWindowsマシン(CPU:Intel Core i5-3470S メモリ:16GB)でいろいろ試していたのですが、実際に学習が動き始めると、さすがにやはりちょっと遅すぎるので、EC2使いました。学習内容によって結構変わってくるみたいですが、だいたい12倍ほど速かったです。もう少し速いとうれしいのですが、しかたないでしょうか?
DNNのフレームワークには、バックエンドにTensorFlowを使ったKerasを使ってみました。
Keras
https://keras.io/
TensorFlow
https://www.tensorflow.org/
Kerasはとても分かりやすくて、私のような素人には本当にありがたい。かなりおすすめです。TensorFlowもですが、本家のドキュメントがしっかりしているのがいいですよね。例えば、今回のケースだと、こんな感じのコードになります。
import numpy as np
from keras.models import Sequential
from keras.layers import Activation, AveragePooling2D, Conv2D, Flatten
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.normalization import BatchNormalization
from keras.optimizers import Adam
BATCH_SIZE = 200
EPOCHS = 20
x_train = np.load('x_train.npy');
y_train = np.load('y_train.npy');
x_test = np.load('x_test.npy');
y_test = np.load('y_test.npy');
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='valid', input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(1, (1, 1), padding='valid'))
model.add(AveragePooling2D(pool_size=(13, 13)))
model.add(Flatten())
model.summary()
model.compile(loss = 'mean_absolute_error',
optimizer = Adam())
model.fit(x_train, y_train,
batch_size = BATCH_SIZE,
epochs = EPOCHS,
verbose = 1,
validation_data = (x_test, y_test))
驚くほどシンプルに書けます。
今回は、以下すべての場合において(ただし、追記に関してはこの限りではありません)、
| バッチサイズ |
200 |
| エポック数 |
20 |
| 損失関数 |
平均絶対誤差(Mean Absolute Error) |
| 最適化アルゴリズム |
Adam(パラメータはKerasのデフォルト) |
です。バッチサイズは、実行速度などに影響がかなり大きいです。エポック数は、収束していなくても、過学習していても、なにがあっても、今回は一定でいきたいと思います。
ネットワークへの入力は、とりあえず最初、「次の手番のプレーヤーの石」と「相手のプレーヤーの石」の2面(19,19,2)、数値は0と1です。ちなみにですが、今回の学習データのラベルは、平均5.7、標準偏差32.9、平均偏差21.5ぐらいです。なので、とりあえず盤面見ないで「黒5.7目形勢が良い」って答えておけば、Lossは21.5にはなりますので(どちらが黒か教えませんので、実際はもう少し難しいはずですが)、最終的にその数字がどれくらい0に近づくのか、っていう感じで見てもらうと良いと思います。
それではいってみましょう。まず最初に考えたのはこんなネットワーク構成でした。
model.add(Conv2D(32, (3, 3), padding='valid', input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(1, (1, 1), padding='valid'))
model.add(Activation('relu'))
model.add(AveragePooling2D(pool_size=(13, 13)))
model.add(Flatten())
model.summary()が吐いてくれるネットワークの要約がこちら。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 17, 17, 32) 608
_________________________________________________________________
activation_1 (Activation) (None, 17, 17, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 15, 15, 32) 9248
_________________________________________________________________
activation_2 (Activation) (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 13, 13, 32) 9248
_________________________________________________________________
activation_3 (Activation) (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 13, 13, 1) 33
_________________________________________________________________
activation_4 (Activation) (None, 13, 13, 1) 0
_________________________________________________________________
average_pooling2d_1 (Average (None, 1, 1, 1) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 1) 0
=================================================================
Total params: 19,137.0
Trainable params: 19,137.0
Non-trainable params: 0.0
パタパタパタと畳んで、ペタンを押しつぶして、フワーと見るイメージなんですが(笑)、ところがこれ、全く学習してくれません。
Epoch 1/20
319200/319200 [==============================] - 29s - loss: 22.3445 - val_loss: 21.9808
Epoch 2/20
319200/319200 [==============================] - 25s - loss: 22.3445 - val_loss: 21.9808
Epoch 3/20
319200/319200 [==============================] - 25s - loss: 22.3445 - val_loss: 21.9808
Epoch 4/20
319200/319200 [==============================] - 25s - loss: 22.3445 - val_loss: 21.9808
Epoch 5/20
319200/319200 [==============================] - 25s - loss: 22.3445 - val_loss: 21.9808
Epoch 6/20
319200/319200 [==============================] - 25s - loss: 22.3445 - val_loss: 21.9808
Epoch 7/20
319200/319200 [==============================] - 25s - loss: 22.3445 - val_loss: 21.9808
Epoch 8/20
319200/319200 [==============================] - 25s - loss: 22.3445 - val_loss: 21.9808
Epoch 9/20
319200/319200 [==============================] - 25s - loss: 22.3445 - val_loss: 21.9808
Epoch 10/20
319200/319200 [==============================] - 25s - loss: 22.3445 - val_loss: 21.9808
Epoch 11/20
319200/319200 [==============================] - 25s - loss: 22.3445 - val_loss: 21.9808
Epoch 12/20
319200/319200 [==============================] - 25s - loss: 22.3445 - val_loss: 21.9808
Epoch 13/20
319200/319200 [==============================] - 25s - loss: 22.3445 - val_loss: 21.9808
Epoch 14/20
319200/319200 [==============================] - 25s - loss: 22.3445 - val_loss: 21.9808
Epoch 15/20
319200/319200 [==============================] - 25s - loss: 22.3445 - val_loss: 21.9808
Epoch 16/20
319200/319200 [==============================] - 25s - loss: 22.3445 - val_loss: 21.9808
Epoch 17/20
319200/319200 [==============================] - 25s - loss: 22.3445 - val_loss: 21.9808
Epoch 18/20
319200/319200 [==============================] - 25s - loss: 22.3445 - val_loss: 21.9808
Epoch 19/20
319200/319200 [==============================] - 25s - loss: 22.3445 - val_loss: 21.9808
Epoch 20/20
319200/319200 [==============================] - 25s - loss: 22.3445 - val_loss: 21.9808
試しに、活性化関数をtanhに変更してみます。
model.add(Conv2D(32, (3, 3), padding='valid', input_shape=x_train.shape[1:]))
model.add(Activation('tanh'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('tanh'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('tanh'))
model.add(Conv2D(1, (1, 1), padding='valid'))
model.add(Activation('tanh'))
model.add(AveragePooling2D(pool_size=(13, 13)))
model.add(Flatten())
Epoch 1/20
319200/319200 [==============================] - 29s - loss: 22.2877 - val_loss: 21.9071
Epoch 2/20
319200/319200 [==============================] - 26s - loss: 22.2663 - val_loss: 21.8958
Epoch 3/20
319200/319200 [==============================] - 26s - loss: 22.2548 - val_loss: 21.8842
Epoch 4/20
319200/319200 [==============================] - 26s - loss: 22.2462 - val_loss: 21.8796
Epoch 5/20
319200/319200 [==============================] - 26s - loss: 22.2417 - val_loss: 21.8763
Epoch 6/20
319200/319200 [==============================] - 26s - loss: 22.2386 - val_loss: 21.8739
Epoch 7/20
319200/319200 [==============================] - 26s - loss: 22.2370 - val_loss: 21.8727
Epoch 8/20
319200/319200 [==============================] - 26s - loss: 22.2341 - val_loss: 21.8692
Epoch 9/20
319200/319200 [==============================] - 26s - loss: 22.2325 - val_loss: 21.8677
Epoch 10/20
319200/319200 [==============================] - 26s - loss: 22.2305 - val_loss: 21.8665
Epoch 11/20
319200/319200 [==============================] - 26s - loss: 22.2290 - val_loss: 21.8653
Epoch 12/20
319200/319200 [==============================] - 26s - loss: 22.2273 - val_loss: 21.8669
Epoch 13/20
319200/319200 [==============================] - 26s - loss: 22.2259 - val_loss: 21.8618
Epoch 14/20
319200/319200 [==============================] - 26s - loss: 22.2245 - val_loss: 21.8624
Epoch 15/20
319200/319200 [==============================] - 26s - loss: 22.2234 - val_loss: 21.8621
Epoch 16/20
319200/319200 [==============================] - 26s - loss: 22.2221 - val_loss: 21.8590
Epoch 17/20
319200/319200 [==============================] - 26s - loss: 22.2208 - val_loss: 21.8604
Epoch 18/20
319200/319200 [==============================] - 26s - loss: 22.2197 - val_loss: 21.8587
Epoch 19/20
319200/319200 [==============================] - 26s - loss: 22.2191 - val_loss: 21.8621
Epoch 20/20
319200/319200 [==============================] - 26s - loss: 22.2178 - val_loss: 21.8557
ちょびっとだけ数字が動いた…(笑) 今度はLeakyReLUに。
model.add(Conv2D(32, (3, 3), padding='valid', input_shape=x_train.shape[1:]))
model.add(LeakyReLU(alpha=0.1))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(LeakyReLU(alpha=0.1))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(LeakyReLU(alpha=0.1))
model.add(Conv2D(1, (1, 1), padding='valid'))
model.add(LeakyReLU(alpha=0.1))
model.add(AveragePooling2D(pool_size=(13, 13)))
model.add(Flatten())
Epoch 1/20
319200/319200 [==============================] - 34s - loss: 21.7510 - val_loss: 20.9956
Epoch 2/20
319200/319200 [==============================] - 30s - loss: 21.1638 - val_loss: 20.7552
Epoch 3/20
319200/319200 [==============================] - 30s - loss: 20.8117 - val_loss: 20.4443
Epoch 4/20
319200/319200 [==============================] - 30s - loss: 20.5938 - val_loss: 20.1891
Epoch 5/20
319200/319200 [==============================] - 30s - loss: 20.3966 - val_loss: 19.9154
Epoch 6/20
319200/319200 [==============================] - 30s - loss: 20.1918 - val_loss: 19.6722
Epoch 7/20
319200/319200 [==============================] - 30s - loss: 20.0177 - val_loss: 19.7719
Epoch 8/20
319200/319200 [==============================] - 30s - loss: 19.8868 - val_loss: 19.3948
Epoch 9/20
319200/319200 [==============================] - 30s - loss: 19.7355 - val_loss: 19.4068
Epoch 10/20
319200/319200 [==============================] - 30s - loss: 19.5322 - val_loss: 19.0625
Epoch 11/20
319200/319200 [==============================] - 30s - loss: 19.3279 - val_loss: 19.1659
Epoch 12/20
319200/319200 [==============================] - 30s - loss: 19.1512 - val_loss: 18.8860
Epoch 13/20
319200/319200 [==============================] - 30s - loss: 18.8963 - val_loss: 18.6369
Epoch 14/20
319200/319200 [==============================] - 30s - loss: 18.6399 - val_loss: 18.4589
Epoch 15/20
319200/319200 [==============================] - 30s - loss: 18.4826 - val_loss: 18.1423
Epoch 16/20
319200/319200 [==============================] - 30s - loss: 18.3363 - val_loss: 18.1451
Epoch 17/20
319200/319200 [==============================] - 30s - loss: 18.1859 - val_loss: 18.0372
Epoch 18/20
319200/319200 [==============================] - 30s - loss: 18.0898 - val_loss: 17.8348
Epoch 19/20
319200/319200 [==============================] - 30s - loss: 18.0122 - val_loss: 17.7273
Epoch 20/20
319200/319200 [==============================] - 30s - loss: 17.9057 - val_loss: 17.9030
おお、がっつり動き始めました! ここで、なんとなく分かりましたよ。現在のネットワーク構成では、一番最後の活性化関数の後ろに、もう畳み込み層や全結合層がありません。活性化関数がひとつ余分なんですね。ReLUは正の値しか出力しないので、それを平均してもまた正の値の出力しか出てきませんが、ラベルの方には負の値(次の手番側が形勢悪い)もあります。その時にパラメータの更新ができないとか、たぶんそういう話です(合ってるかな?)。ということで、活性化関数をReLUに戻して、一番最後のは削ります。
model.add(Conv2D(32, (3, 3), padding='valid', input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(1, (1, 1), padding='valid'))
model.add(AveragePooling2D(pool_size=(13, 13)))
model.add(Flatten())
Epoch 1/20
319200/319200 [==============================] - 29s - loss: 21.7389 - val_loss: 20.8649
Epoch 2/20
319200/319200 [==============================] - 25s - loss: 20.8634 - val_loss: 20.4426
Epoch 3/20
319200/319200 [==============================] - 25s - loss: 19.7709 - val_loss: 19.0222
Epoch 4/20
319200/319200 [==============================] - 25s - loss: 19.1506 - val_loss: 18.5475
Epoch 5/20
319200/319200 [==============================] - 25s - loss: 18.7009 - val_loss: 18.1697
Epoch 6/20
319200/319200 [==============================] - 25s - loss: 18.3530 - val_loss: 17.9657
Epoch 7/20
319200/319200 [==============================] - 25s - loss: 18.1615 - val_loss: 17.7496
Epoch 8/20
319200/319200 [==============================] - 25s - loss: 18.0063 - val_loss: 17.8551
Epoch 9/20
319200/319200 [==============================] - 25s - loss: 17.9094 - val_loss: 17.5887
Epoch 10/20
319200/319200 [==============================] - 25s - loss: 17.8051 - val_loss: 17.4792
Epoch 11/20
319200/319200 [==============================] - 25s - loss: 17.7149 - val_loss: 17.4250
Epoch 12/20
319200/319200 [==============================] - 25s - loss: 17.6149 - val_loss: 17.3268
Epoch 13/20
319200/319200 [==============================] - 25s - loss: 17.5354 - val_loss: 17.7732
Epoch 14/20
319200/319200 [==============================] - 25s - loss: 17.4814 - val_loss: 17.6514
Epoch 15/20
319200/319200 [==============================] - 25s - loss: 17.3799 - val_loss: 17.4220
Epoch 16/20
319200/319200 [==============================] - 25s - loss: 17.3349 - val_loss: 17.0786
Epoch 17/20
319200/319200 [==============================] - 25s - loss: 17.2229 - val_loss: 17.1846
Epoch 18/20
319200/319200 [==============================] - 25s - loss: 17.1549 - val_loss: 16.9264
Epoch 19/20
319200/319200 [==============================] - 25s - loss: 17.1092 - val_loss: 17.0422
Epoch 20/20
319200/319200 [==============================] - 25s - loss: 17.0327 - val_loss: 18.2891
OKのようです。
LeakyReLUってなんとなく好きなんですが、ReLUの方がやはり軽いみたいなので、ここから先はひとまずReLUを使います。
次に、ネットワークを深くしていきます。3×3の畳み込み層を全部で4層に。
model.add(Conv2D(32, (3, 3), padding='valid', input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(1, (1, 1), padding='valid'))
model.add(AveragePooling2D(pool_size=(11, 11)))
model.add(Flatten())
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 17, 17, 32) 608
_________________________________________________________________
activation_1 (Activation) (None, 17, 17, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 15, 15, 32) 9248
_________________________________________________________________
activation_2 (Activation) (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 13, 13, 32) 9248
_________________________________________________________________
activation_3 (Activation) (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 11, 11, 32) 9248
_________________________________________________________________
activation_4 (Activation) (None, 11, 11, 32) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 11, 11, 1) 33
_________________________________________________________________
average_pooling2d_1 (Average (None, 1, 1, 1) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 1) 0
=================================================================
Total params: 28,385.0
Trainable params: 28,385.0
Non-trainable params: 0.0
そして5層、6層、7層、8層、と増やしていって、最後に全部で9層。今回はパディングを入れていないので、どんどん畳み込まれていって、3×3の畳み込みのみで1×1のサイズに。そうなると、最後の平均プーリングはもう意味がありませんので削除します。1×1の畳み込み層も、実質、ただの全結合になってしまいました。
model.add(Conv2D(32, (3, 3), padding='valid', input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(1, (1, 1), padding='valid'))
model.add(Flatten())
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 17, 17, 32) 608
_________________________________________________________________
activation_1 (Activation) (None, 17, 17, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 15, 15, 32) 9248
_________________________________________________________________
activation_2 (Activation) (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 13, 13, 32) 9248
_________________________________________________________________
activation_3 (Activation) (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 11, 11, 32) 9248
_________________________________________________________________
activation_4 (Activation) (None, 11, 11, 32) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 9, 9, 32) 9248
_________________________________________________________________
activation_5 (Activation) (None, 9, 9, 32) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 7, 7, 32) 9248
_________________________________________________________________
activation_6 (Activation) (None, 7, 7, 32) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 5, 5, 32) 9248
_________________________________________________________________
activation_7 (Activation) (None, 5, 5, 32) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 3, 3, 32) 9248
_________________________________________________________________
activation_8 (Activation) (None, 3, 3, 32) 0
_________________________________________________________________
conv2d_9 (Conv2D) (None, 1, 1, 32) 9248
_________________________________________________________________
activation_9 (Activation) (None, 1, 1, 32) 0
_________________________________________________________________
conv2d_10 (Conv2D) (None, 1, 1, 1) 33
_________________________________________________________________
flatten_1 (Flatten) (None, 1) 0
=================================================================
Total params: 74,625.0
Trainable params: 74,625.0
Non-trainable params: 0.0
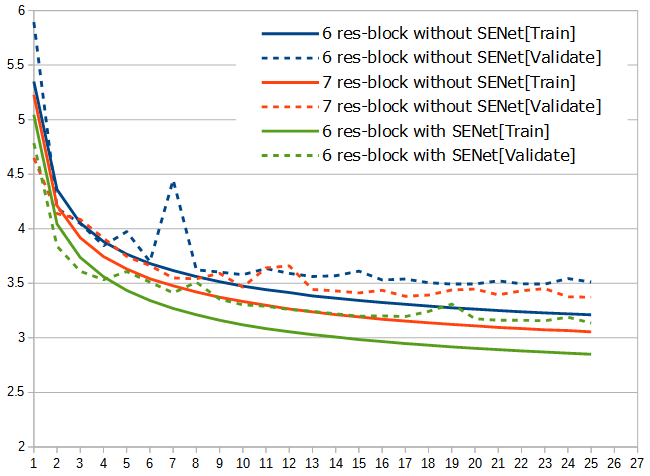
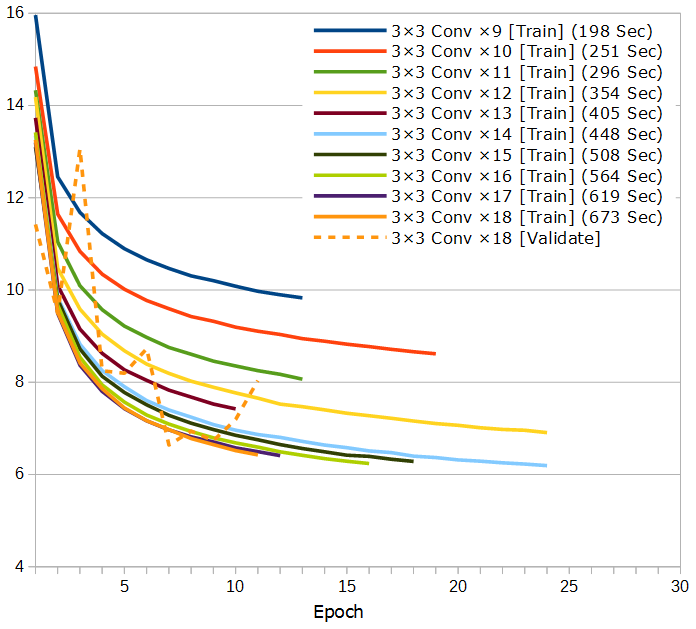
3層~9層すべてのTrain Lossをグラフにしてみます。カッコ内の秒数は、2エポック目に掛かった時間です。だいたいこれが、1エポックあたりの平均の実行時間になります。
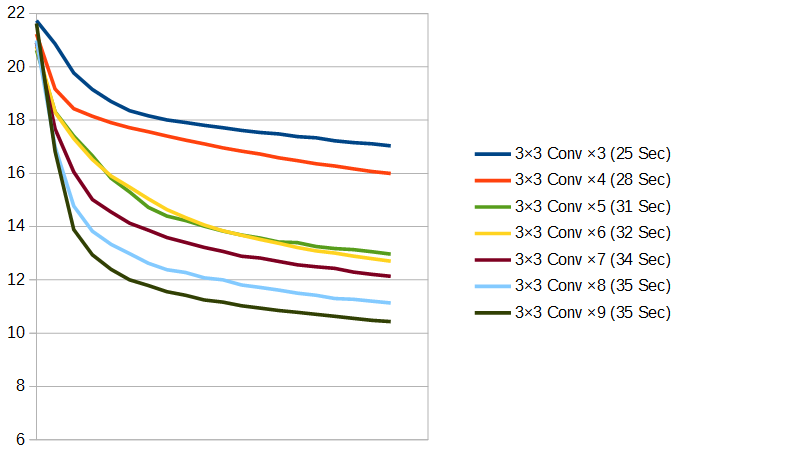
ネットワークが深くなるにつれ、どんどん賢くなっていくのがよく分かります。しかし、小さく畳み込まれたのをさらに畳み込んでいっているので、学習時間はあまり増えていきません。とはいえ、パラメータ数はどんどん増えていくので、過学習しやすくなったりはしてそうです。
パディングを入れれば、3×3の畳み込みをもっと重ねていくことは可能ですが、ここから先はひとまず9層で続けていきます。
次は、畳み込み層のフィルターの数を増やしていきたいと思います。まずは48に。
model.add(Conv2D(48, (3, 3), padding='valid', input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(48, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(48, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(48, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(48, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(48, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(48, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(48, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(48, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(1, (1, 1), padding='valid'))
model.add(Flatten())
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 17, 17, 48) 912
_________________________________________________________________
activation_1 (Activation) (None, 17, 17, 48) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 15, 15, 48) 20784
_________________________________________________________________
activation_2 (Activation) (None, 15, 15, 48) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 13, 13, 48) 20784
_________________________________________________________________
activation_3 (Activation) (None, 13, 13, 48) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 11, 11, 48) 20784
_________________________________________________________________
activation_4 (Activation) (None, 11, 11, 48) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 9, 9, 48) 20784
_________________________________________________________________
activation_5 (Activation) (None, 9, 9, 48) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 7, 7, 48) 20784
_________________________________________________________________
activation_6 (Activation) (None, 7, 7, 48) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 5, 5, 48) 20784
_________________________________________________________________
activation_7 (Activation) (None, 5, 5, 48) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 3, 3, 48) 20784
_________________________________________________________________
activation_8 (Activation) (None, 3, 3, 48) 0
_________________________________________________________________
conv2d_9 (Conv2D) (None, 1, 1, 48) 20784
_________________________________________________________________
activation_9 (Activation) (None, 1, 1, 48) 0
_________________________________________________________________
conv2d_10 (Conv2D) (None, 1, 1, 1) 49
_________________________________________________________________
flatten_1 (Flatten) (None, 1) 0
=================================================================
Total params: 167,233.0
Trainable params: 167,233.0
Non-trainable params: 0.0
次は64に。
model.add(Conv2D(64, (3, 3), padding='valid', input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(Conv2D(1, (1, 1), padding='valid'))
model.add(Flatten())
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 17, 17, 64) 1216
_________________________________________________________________
activation_1 (Activation) (None, 17, 17, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 15, 15, 64) 36928
_________________________________________________________________
activation_2 (Activation) (None, 15, 15, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 13, 13, 64) 36928
_________________________________________________________________
activation_3 (Activation) (None, 13, 13, 64) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 11, 11, 64) 36928
_________________________________________________________________
activation_4 (Activation) (None, 11, 11, 64) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 9, 9, 64) 36928
_________________________________________________________________
activation_5 (Activation) (None, 9, 9, 64) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 7, 7, 64) 36928
_________________________________________________________________
activation_6 (Activation) (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 5, 5, 64) 36928
_________________________________________________________________
activation_7 (Activation) (None, 5, 5, 64) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 3, 3, 64) 36928
_________________________________________________________________
activation_8 (Activation) (None, 3, 3, 64) 0
_________________________________________________________________
conv2d_9 (Conv2D) (None, 1, 1, 64) 36928
_________________________________________________________________
activation_9 (Activation) (None, 1, 1, 64) 0
_________________________________________________________________
conv2d_10 (Conv2D) (None, 1, 1, 1) 65
_________________________________________________________________
flatten_1 (Flatten) (None, 1) 0
=================================================================
Total params: 296,705.0
Trainable params: 296,705.0
Non-trainable params: 0.0
フィルター数の違いを、グラフにしてみます。
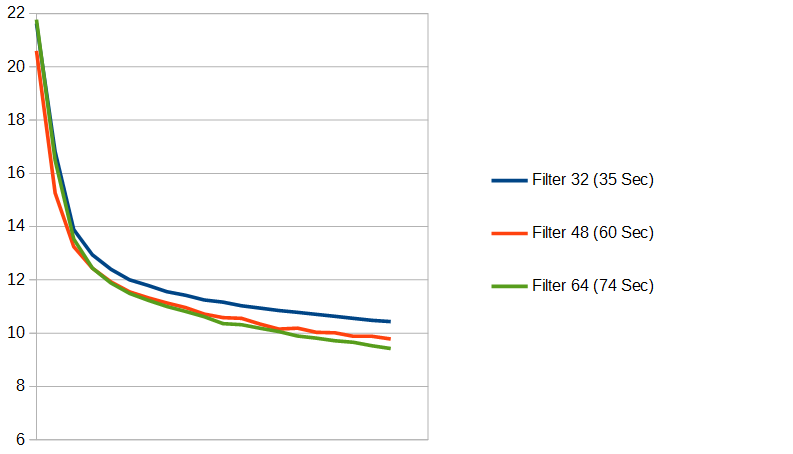
これも増やせば増やすほど、賢くなっていきますが、学習時間の増え方もすごいですね。フィルター数64の時のTotal paramsは30万近くに… 身の丈に合っていないような気がするので(笑)、ここから先はひとまずフィルター数は32で続けていきます。
ここまでは、ネットワーク構成をいろいろ試してきましたが、ここで一度、ネットワークに対する入力を変更してみたいと思います。今現在は、石の配置の2面だけですが、これに「その場所の石のダメの数」を加えた3面にしてみました。数値はtanh(ダメの数*0.05)して0と1の間に収めました(0~1に正規化するのは、Kerasのサンプルがそうなっていたので)。ダメの数/256やmin(1, ダメの数/32)など、まあ何でもいいような気はします。ところで19路盤の最大ダメ数っていくらなんでしょう?
ダメなしとダメありとでの違いを、グラフにしてみます。
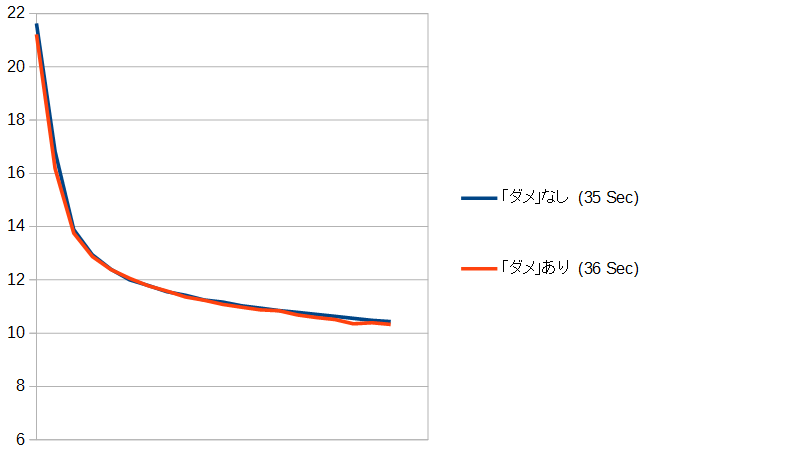
うーん、ちょっと効果が薄いですね。実は劇的に良くなるかと期待していたのですが… ダメの数は特に必要な情報でないからなのか、石の配置を見ればそんなことは分かるからなのかちょっとはっきりしませんが、ネットワークへの入力でがんばれることは、意外とあんまり無いのかもしれません。とはいえ、効果が全く無いわけではないので、ここから先はひとまず入力はダメありの3面で続けていきます。
次は、みんな大好き(笑)Batch Normalizationです。私は当初、Batch Normalizationって畳み込み層や全結合層の前に置くものだと、完全に思い込んでいたのですが、どうやら活性化関数の前に置くのが正しい? そのあたりも含めて調べてみます。
まずは、活性化関数の前にBatch Normalizationを置くバージョン。
model.add(Conv2D(32, (3, 3), padding='valid', input_shape=x_train.shape[1:]))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(1, (1, 1), padding='valid'))
model.add(Flatten())
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 17, 17, 32) 896
_________________________________________________________________
batch_normalization_1 (Batch (None, 17, 17, 32) 128
_________________________________________________________________
activation_1 (Activation) (None, 17, 17, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 15, 15, 32) 9248
_________________________________________________________________
batch_normalization_2 (Batch (None, 15, 15, 32) 128
_________________________________________________________________
activation_2 (Activation) (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 13, 13, 32) 9248
_________________________________________________________________
batch_normalization_3 (Batch (None, 13, 13, 32) 128
_________________________________________________________________
activation_3 (Activation) (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 11, 11, 32) 9248
_________________________________________________________________
batch_normalization_4 (Batch (None, 11, 11, 32) 128
_________________________________________________________________
activation_4 (Activation) (None, 11, 11, 32) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 9, 9, 32) 9248
_________________________________________________________________
batch_normalization_5 (Batch (None, 9, 9, 32) 128
_________________________________________________________________
activation_5 (Activation) (None, 9, 9, 32) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 7, 7, 32) 9248
_________________________________________________________________
batch_normalization_6 (Batch (None, 7, 7, 32) 128
_________________________________________________________________
activation_6 (Activation) (None, 7, 7, 32) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 5, 5, 32) 9248
_________________________________________________________________
batch_normalization_7 (Batch (None, 5, 5, 32) 128
_________________________________________________________________
activation_7 (Activation) (None, 5, 5, 32) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 3, 3, 32) 9248
_________________________________________________________________
batch_normalization_8 (Batch (None, 3, 3, 32) 128
_________________________________________________________________
activation_8 (Activation) (None, 3, 3, 32) 0
_________________________________________________________________
conv2d_9 (Conv2D) (None, 1, 1, 32) 9248
_________________________________________________________________
batch_normalization_9 (Batch (None, 1, 1, 32) 128
_________________________________________________________________
activation_9 (Activation) (None, 1, 1, 32) 0
_________________________________________________________________
conv2d_10 (Conv2D) (None, 1, 1, 1) 33
_________________________________________________________________
flatten_1 (Flatten) (None, 1) 0
=================================================================
Total params: 76,065.0
Trainable params: 75,489.0
Non-trainable params: 576.0
長い…(笑) 次は、活性化関数の後にBatch Normalizationを置くバージョン。
model.add(Conv2D(32, (3, 3), padding='valid', input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Conv2D(32, (3, 3), padding='valid'))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Conv2D(1, (1, 1), padding='valid'))
model.add(Flatten())
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 17, 17, 32) 896
_________________________________________________________________
activation_1 (Activation) (None, 17, 17, 32) 0
_________________________________________________________________
batch_normalization_1 (Batch (None, 17, 17, 32) 128
_________________________________________________________________
conv2d_2 (Conv2D) (None, 15, 15, 32) 9248
_________________________________________________________________
activation_2 (Activation) (None, 15, 15, 32) 0
_________________________________________________________________
batch_normalization_2 (Batch (None, 15, 15, 32) 128
_________________________________________________________________
conv2d_3 (Conv2D) (None, 13, 13, 32) 9248
_________________________________________________________________
activation_3 (Activation) (None, 13, 13, 32) 0
_________________________________________________________________
batch_normalization_3 (Batch (None, 13, 13, 32) 128
_________________________________________________________________
conv2d_4 (Conv2D) (None, 11, 11, 32) 9248
_________________________________________________________________
activation_4 (Activation) (None, 11, 11, 32) 0
_________________________________________________________________
batch_normalization_4 (Batch (None, 11, 11, 32) 128
_________________________________________________________________
conv2d_5 (Conv2D) (None, 9, 9, 32) 9248
_________________________________________________________________
activation_5 (Activation) (None, 9, 9, 32) 0
_________________________________________________________________
batch_normalization_5 (Batch (None, 9, 9, 32) 128
_________________________________________________________________
conv2d_6 (Conv2D) (None, 7, 7, 32) 9248
_________________________________________________________________
activation_6 (Activation) (None, 7, 7, 32) 0
_________________________________________________________________
batch_normalization_6 (Batch (None, 7, 7, 32) 128
_________________________________________________________________
conv2d_7 (Conv2D) (None, 5, 5, 32) 9248
_________________________________________________________________
activation_7 (Activation) (None, 5, 5, 32) 0
_________________________________________________________________
batch_normalization_7 (Batch (None, 5, 5, 32) 128
_________________________________________________________________
conv2d_8 (Conv2D) (None, 3, 3, 32) 9248
_________________________________________________________________
activation_8 (Activation) (None, 3, 3, 32) 0
_________________________________________________________________
batch_normalization_8 (Batch (None, 3, 3, 32) 128
_________________________________________________________________
conv2d_9 (Conv2D) (None, 1, 1, 32) 9248
_________________________________________________________________
activation_9 (Activation) (None, 1, 1, 32) 0
_________________________________________________________________
batch_normalization_9 (Batch (None, 1, 1, 32) 128
_________________________________________________________________
conv2d_10 (Conv2D) (None, 1, 1, 1) 33
_________________________________________________________________
flatten_1 (Flatten) (None, 1) 0
=================================================================
Total params: 76,065.0
Trainable params: 75,489.0
Non-trainable params: 576.0
これも、グラフにします。今回はValidate Loss付きです。
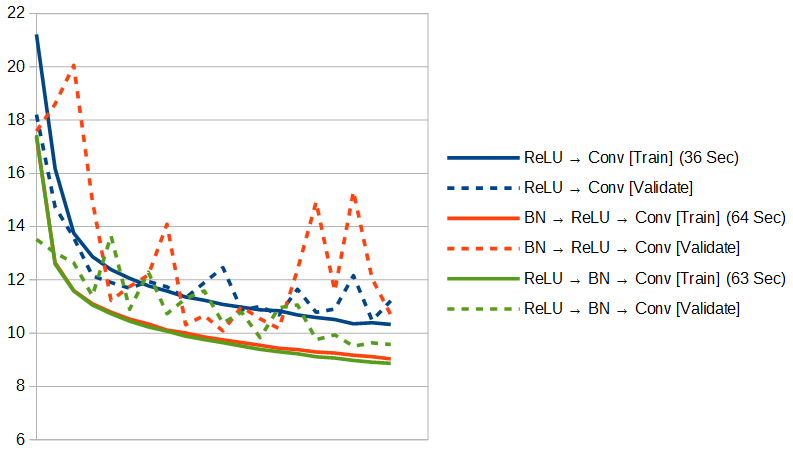
もう少したくさん学習させてみないと、最終的に収束した時のLossが低くなるのか、学習が速いだけなのか、よく分かりませんが、なんにせよ、とりあえずBatch Normalizationはすばらしい! Validate Lossも10をはっきりと切ってきました。みんな大好きBatch Normalization、僕も大好きです(笑)。1エポックあたりの学習時間は大幅に増えて、たしかに重いのは重いんですが、学習が速くなるのであれば、それも少なくともある程度はペイしそうです。
そして、先ほどの「Batch Normalizationは活性化関数の前なのか後なのか問題」ですが、今回のケースでは、「活性化関数の後」が良さそうです。平均した数字だけ見てもそうなのですが、「活性化関数の前」のValidate Lossの上下にバタバタする感じがちょっと気持ち悪い… ただ、今回は検証用データの量が絶対的に少ないので、もう少しちゃんと調べないと、はっきりしたことは言えません。
今後は、ひとまず「活性化関数の後」にBatch Normalizationを置く形で続けていきます。
いやあ、それにしても長い記事になりました。しかも、まだぜんぜん終わってない… たぶん、大量に追記することになります。
ここまで、やってきて一番思うのは、「学習データって大事」ってことです。これは量も質もですね。最初始めた時、「学習データなんてなんでもいいよ。俺はディープなラーニングがしたいだけなんだよ」って思ってた自分を引っ叩いてやりたい(笑)。ただ、当初はここまで良い数字が出るとは、正直思ってなかったから、ということもあります。例えば、今現在のようなネットワーク構成でも、もう少しネットワークを深くして、もう少しフィルターを増やして、学習データ増やして、ワンコインぐらい課金すれば、Validate Lossが7ぐらいまでいけそうですが、そこまでいければ、今回の評価関数は(も?)同じような盤面は同じように形勢判断を間違えるのだろうと思うので、深さ1の全幅と組み合わせて、GNU Goぐらいならなんとか勝てないでしょうか? もし仮にそれができたら、Keras.js使って、もうこれは何て言うか一丁上がりなんですが、なかなか事前にそこまで夢みることはできませんでした。
そういう訳で、とにかく学習データです。今現在、COSUMIのサーバを使って学習データを大量に作成中です(負荷が低くなったら、自動的に作り始めるようにした)。それができあがったら、また引き続きいろいろ試してみたいと思います。
[追記 2017/5/2]
あの後、学習データをたくさん作りました。まずは、前回使用したデータと今回分との、形勢の分布のグラフを。比較しやすいように、スケールは調整してあります。
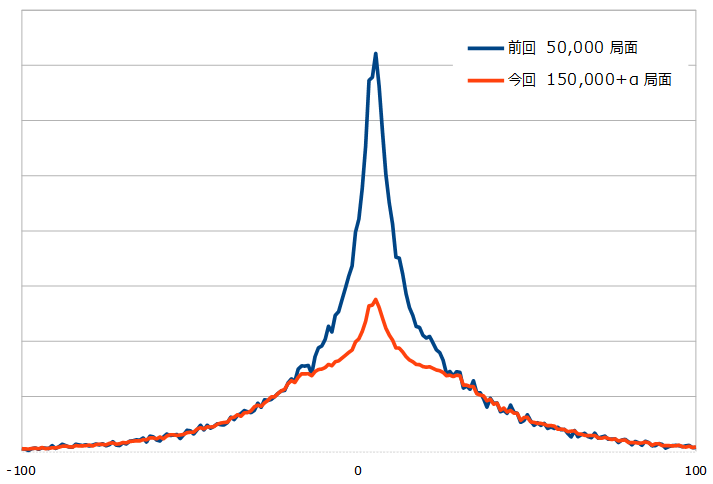
前回分のデータの分布を最初に見た時、いくらなんでもこれは分散が足らないんじゃないかと思ったので、今回は平均近辺を適当に間引きながらデータを作成したのですが、あんまりきれいな間引き方になっていないような気がして、少しもったいなかったのですが、思いきって新規作成分の平均近辺をスクエアにぱすっと捨てて、それに前回作成分を足しました。えっと、なに言っている分からないと思いますが(笑)、とにかくグラフのような感じに、真ん中減らしました。前回、21.5だった平均偏差は27.8に。そこだけでいうと、今回の方が厳しいデータセットになっていると思います。
今回使用分は15万局面分+α。これを対称形に8倍して、切り良く120万局面分に減らしました。そして、前回と同じく、その内80%を学習用に、残りの20%を検証用に使用します。
この新しい学習データで、前回最後のネットワーク構成から試してみたいと思います。現在地をおさらいすると、
- 入力は「手番のプレーヤーの石の配置」「相手の石の配置」「その場所にある石のダメの数」の3面(19,19,3)
- 3×3の畳み込み層が9層、1×1の畳み込み層が1層、フィルター数は最後以外32
- 活性化関数は全部ReLU
- ReLUの後にBatch Normalization
です。さらに今回はここから、入力層の所にパディング付の3×3の畳み込み層を追加していく形で、どんどん深くしてみました。最後は3×3の畳み込み層が18層です。今回はエポック数は固定にしないで、Validate Lossが下げ止まったら、学習を止めるようにしました。話が少しそれますが、Kerasには、そういう時に使うkeras.callbacks.EarlyStoppingというコールバック関数が用意されているのですが、それのpatienceという引数についてのまともな説明が、ウェブ上にほとんど無い! これは本家のドキュメントも一緒で、例えば、日本語版ではこうなってます。
patience: トレーニングが停止し,値が改善しなくなった時のエポック数.
なにを言っているのか、まじでぜんぜん分からん…(笑) 次に本家英語版。
patience: number of epochs with no improvement after which training will be stopped.
私の英語力が確かなら、これも間違っています。例えば、patience=1の時は、最高なり最低なりを1回でも更新できなかったらそこですぐに止まるわけではなく、2回連続して更新できなかったら止まるんです。patience=2の時は、3回です。1回でも更新できなかったらすぐ止まるpatience=0を基準に、さらに何回待つかっていうのがこのpatienceですよ。みなさん気をつけてください。で、今回は最初の「3×3の畳み込み層が9層」の時のみpatience=2(ちょっと少なかった。加減が結構難しい…)、10層からはpatience=3に設定してみました。
うーん、もうネットワークを深くすれば良いだけなのかな? 簡単に数字が良くなっていきます。もっと早くサチるかと思っていたのに、なかなか止まらないので、気持ちよくお金が溶けていきました…(泣) 「こんな風に深くするだけでいいんであれば、小細工なしにResNetってやつをやれば終了じゃない?」ということで、前半部分にショートカットを入れたバージョンの14層と18層も追加で試してみました。先ほどのpatienceは4にしました。14層ならコードはこんな感じ。本当にこれで良いのか、かなり不安ですが…
input = Input(shape=x_train.shape[1:])
fork = Conv2D(32, (3, 3), padding='same')(input)
main = Activation('relu')(fork)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
main = Activation('relu')(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
fork = add([main, fork])
main = Activation('relu')(fork)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
main = Activation('relu')(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
main = add([main, fork])
main = Activation('relu')(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='valid')(main)
main = Activation('relu')(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='valid')(main)
main = Activation('relu')(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='valid')(main)
main = Activation('relu')(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='valid')(main)
main = Activation('relu')(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='valid')(main)
main = Activation('relu')(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='valid')(main)
main = Activation('relu')(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='valid')(main)
main = Activation('relu')(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='valid')(main)
main = Activation('relu')(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='valid')(main)
main = Activation('relu')(main)
main = BatchNormalization()(main)
main = Conv2D(1, (1, 1), padding='valid')(main)
output = Flatten()(main)
model = Model(inputs=input, outputs=output)
ショートカットあるなしで比較してみます。
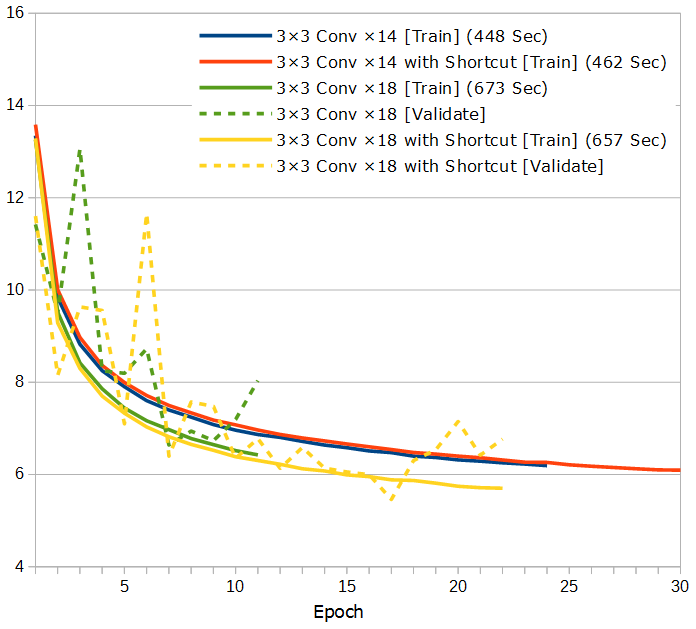
「18層の時は、もしかしたらショートカットが効いてるのかな?」ってぐらいですね。そもそも、この程度ではまだぜんぜんネットワークが深すぎるっていうほどのものじゃないのかもしれません。深くしたからサチったのではなくて、そろそろ学習データの精度の問題かも…
ここで一度、現在作っている評価関数が実際にどんな形勢判断を返してくるのか確認することにしてみました。使った評価関数のバージョンは、先ほどの「3×3の畳み込み層が18層/ショートカットあり」。これに、検証用データの先頭200局面分を予測させた時の数値のグラフがこちらです。
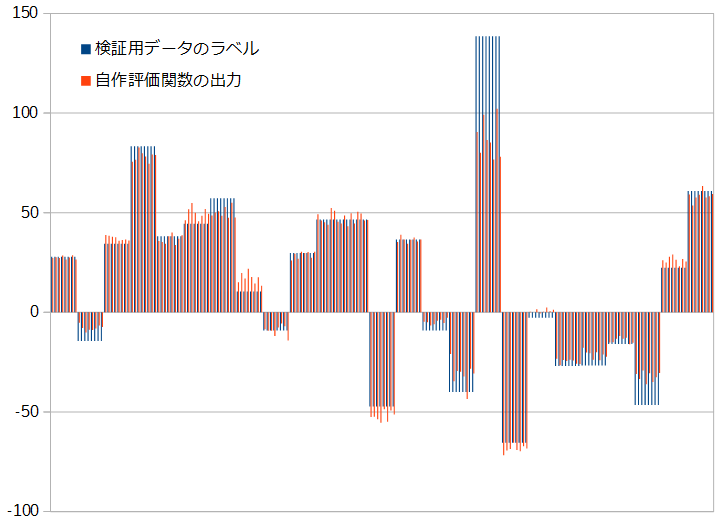
当たり前の話なんですが、本当に形勢判断できるんですね(笑)。感動します。ただ、ちょっと気になることもあって、この検証用データのラベルが8つずつ全く同じのが続くのは、同じ局面の対称形が連続して並んでいるからなんですが、評価関数の出力の方はなかなかきれいに揃わないですね。これを「まだ伸び代がある」とか、「対称形8つ全部を順番に評価関数に入れて平均とったら精度上がるんじゃない?」とか、ポジティブに捉えることもできなくはないかもしれませんが、個人的にはこういうのはただただ気持ち悪いです… こうなる理由として考えられるのは、「3×3の畳み込み層のフィルタの初期値が対称形でないから」とか、「学習用データに対称形がすべて含まれているけど、学習するタイミングが前後するので、先に学習した、後に学習したでモデルに与える影響が変わってくるから」とかあたりでしょうか? これはまた調べてみたいですね。
今回の200局面分の予測の中で検証用データのラベルと一番食い違っているのが、グラフ中央右寄りにある100を超えているやつなので、この局面を探して実際に盤面を見てみることにしました。それがこちら。
Sorry, your browser doesn’t support WGo.js.
検証用データのラベルは約138.61。これは、「コミがないとすれば次の手番である白が138.61目勝っている」の意味です。最初に盤面で確認しておかないといけないのは、下辺の黒の大石の死活ですが、これはセキにはなりますが生きてますね(見損じしてないよね?)。だとすると、形勢は白100目弱勝ちぐらいでしょうか? 自作評価関数の出力は対称形8つの平均で87.31。おお、自作評価関数の方がだいぶ近い… 先生より正確とはやるじゃん!(笑) まあ、「石いっぱいあるから強ーい」ぐらいに思っているだけで(笑)、Ray先生のような高度な判断をしている訳ではないような気がしますが、とはいえ、こういった不正確なラベルのせいで、40目も余分に間違えていることにされるようなことがちょくちょくあったら、下がるはずのLossも下がりません。「機械学習では質の良い学習データを大量に用意することが肝心」、という結論にまた落ち着いてしまいますね。ということで、現在、学習データの精度を上げるべく、COSUMIのサーバをまたぶん回しております。いつか、学習データの作成自体を、この評価関数にやらせたいですね。それができれば、量の問題は一発で解決なんですが…
[追記 2017/6/11]
あの後、ASUSのSTRIX-GTX1060-DC2O6GっていうGTX1060・メモリ6GBなビデオカード買いました。EC2への課金が100ドルを超えてきたので、EC2使い続けるのか、別の方法を取るのか、今決めてしまわないといけないと思い、かなりいろいろ考えて、結局GPU買っちゃいました。最初は、GPU買うなら中途半端はだめで、1080ti一択だなと思い込んでいたのですが、そうなってくると電源ユニットの買い直しが確定するので、それがちょっとなあと思っていました。けれども、よく調べてみると、その下のグレードでも十分実用性がありそうですし、なによりはるかに安いので、こういう選択肢になりました。1070でも良かったけど、電源が100%自信が持てなかったので1060に。使っているマザーはASUSのP8H77-Vで、H77と最近のビデオカードとでは動かない時がある、という話を見て少し心配していたのですが、全く問題ありませんでした。このビデオカードは、温度が低い時にファンが完全に止まる静音設計で、それも購入にあたって重視していた点なのですが、そもそもファンが回っていても、めちゃくちゃ静かです。良い買い物でした。こんな高価なビデオカードを買うのは、もちろん初めてですし、ビデオカード自体、一番最後に買ったのはいつのことだろう… Rage Fury MAXX(笑)が最後かな?(一番最後まで使っていたのは、たぶんG400) ちなみに、今現在のメインメモリは16GBなんですが、GPU買ってしまうと、今度はこれを32GBに増やしたくて仕方がない…(笑) ただ、4年半前に買った時は5,880円だった物が、今現在、値段が倍以上する感じで萎えまくりです。うーん、どうしたものか…
そして、学習データもこの前使っていたものを、さらに50k playoutで2目ずつずらしていく形でラベル付け直して精度を上げてみました(この前までは、20k playoutで4目ずつ)。量も少し増やして、計159万局面分。今までと同じく、その内80%を学習用に、残りの20%を検証用に使用します。
ということで、新しいGPUと新しいデータでいろいろ試してみましたが、結局一番数字が良くなるのは、次のようなパディングとショートカットを入れながら、ひたすら3×3の畳み込み層を重ねるだけというシンプルなやつでした。
input = Input(shape=x_train.shape[1:])
fork = Conv2D(32, (3, 3), padding='same')(input)
main = Activation("relu")(fork)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
main = Activation("relu")(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
fork = add([main, fork])
main = Activation("relu")(fork)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
main = Activation("relu")(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
fork = add([main, fork])
main = Activation("relu")(fork)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
main = Activation("relu")(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
fork = add([main, fork])
main = Activation("relu")(fork)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
main = Activation("relu")(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
fork = add([main, fork])
main = Activation("relu")(fork)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
main = Activation("relu")(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
fork = add([main, fork])
main = Activation("relu")(fork)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
main = Activation("relu")(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
fork = add([main, fork])
main = Activation("relu")(fork)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
main = Activation("relu")(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
fork = add([main, fork])
main = Activation("relu")(fork)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
main = Activation("relu")(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
fork = add([main, fork])
main = Activation("relu")(fork)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
main = Activation("relu")(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
fork = add([main, fork])
main = Activation("relu")(fork)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
main = Activation("relu")(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
fork = add([main, fork])
main = Activation("relu")(fork)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
main = Activation("relu")(main)
main = BatchNormalization()(main)
main = Conv2D(32, (3, 3), padding='same')(main)
main = add([main, fork])
main = Activation("relu")(main)
main = BatchNormalization()(main)
main = Conv2D(1, (3, 3), padding='valid')(main)
main = AveragePooling2D(pool_size=(17, 17))(main)
output = Flatten()(main)
model = Model(inputs=input, outputs=output)
ショートカットなし版との比較がこちら。
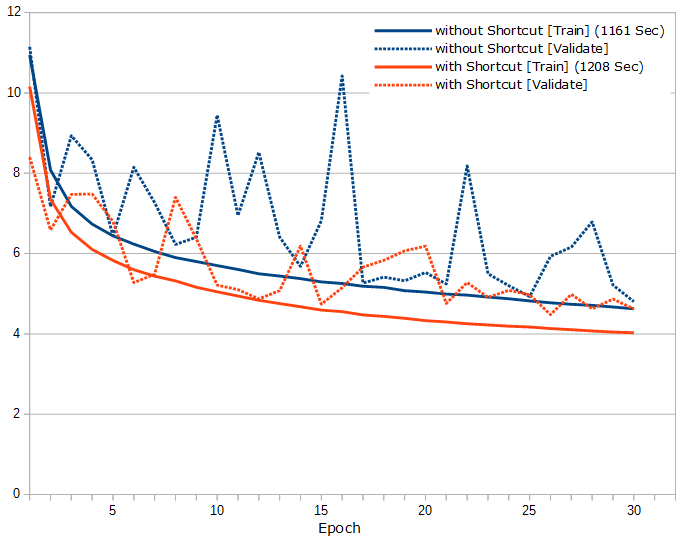
ショートカットは、はっきり効果があるようです。そして問題は、深くするのが良いのか広くするのが良いのかなんですが、まずはフィルタ数を32で固定して、3×3の畳み込み層が24層、32層、40層の比較がこちら。
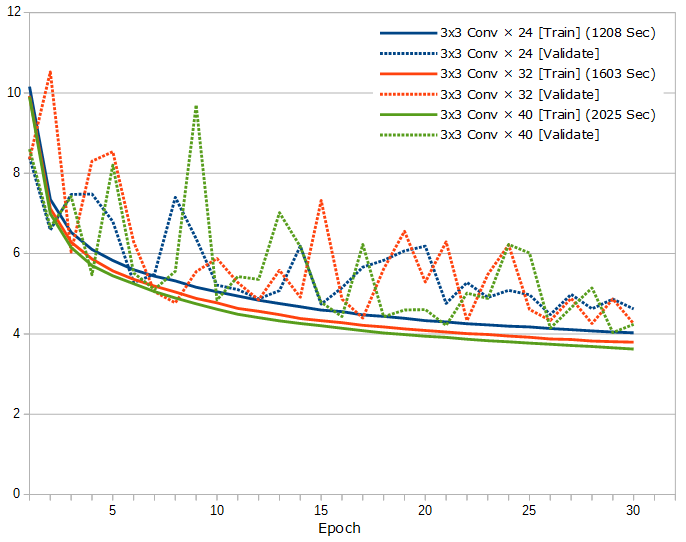
そして次に、3×3の畳み込み層を24層に固定して、フィルタ数が32、48、64の比較がこちら。
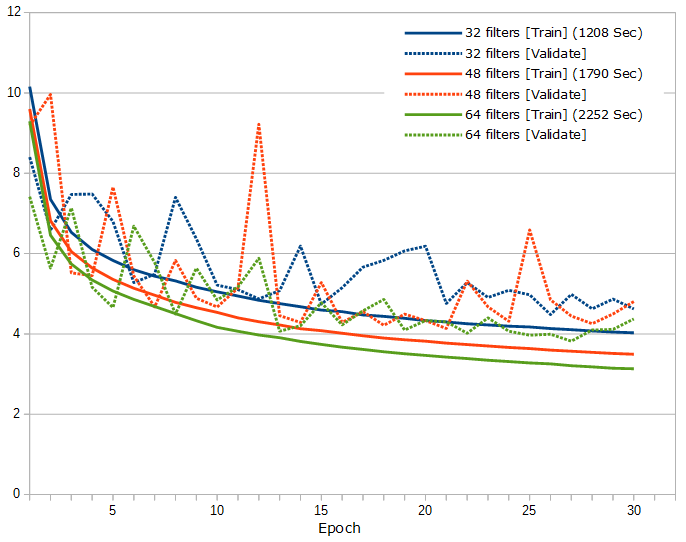
それ以外にもいろいろ試した結果としては、
- ReLUとBatch Normalizationの順番は、BN -> ReLU -> ConvよりReLU -> BN -> Convの方が、やはり良さそう
- 入力は、「だめの数なし」より「だめの数あり」の方が、やはり少し数字が良い
- オプティマイザにNesterov MomentumなSGDを少し試してみたけど、特に良さそうには見えない
といった感じでしょうか。
数字はだいぶ良くなってきたので、本当に何か使い道も考えてみたいですね。
[追記 2017/6/14]
今のデータ量で行けるところまでやってみようと、3×3の畳み込み層が30層、フィルタ数が48で50エポック回してみました。さらに、その30エポック目からAdamの学習率をKerasのデフォルト(そしてそれは論文の推奨値だそうです)の1e-3から1e-4に小さくしたのと、またさらに、その40エポック目から学習率を1e-5に小さくしたのとのグラフがこちら。
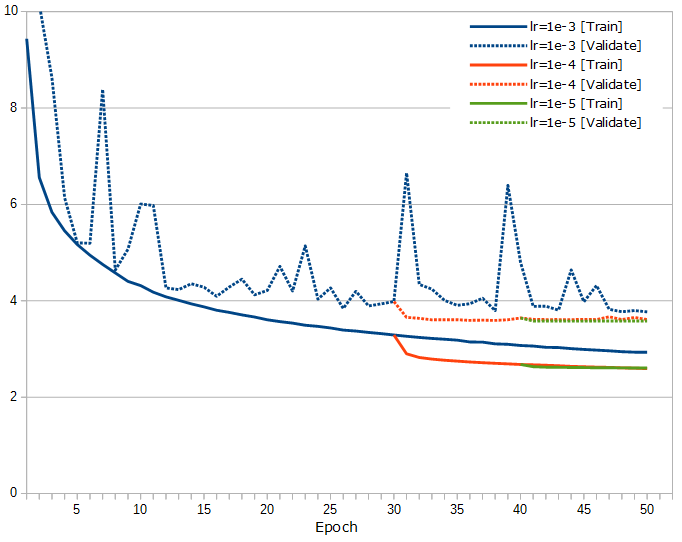
この学習率を下げるのは手動でやっているのですが、本当はこのあたり、コンピュータにスマートによろしくやってもらわないといけないのでしょうね。keras.callbacks.LearningRateScheduler()使ったり、keras.optimizers.Adam()のdecayを設定すれば良いのかなと、少し試してみたりもしましたが、結局どのくらいずつ下げていけば良いのか事前にはっきり分からないので、もう手動でもいいかな…
それと、学習率下げてはっきりしましたが、最後はほんの少し過学習ぎみですね。対称形に8倍して1,272,000局面分のデータ量では、Trainable paramsが586,513の今回の大きさのネットワークあたりが限界かな、という気がしてます。
しかしそれにしても、数字がかなりよくなってきて、Validate Lossは3.6(!)を切ってきました。そんなのもう、ほとんどRay由来のノイズじゃないのかと思ってしまいます。というより、データ作成で何かやらかしていないか、心配になるレベルなのですが…(笑)
[追記 2017/8/2]
KerasのConv2Dのkernel_initializerのデフォルトは、Glorot uniformってやつなんですが、He uniformも試して比較してみました(本当に申し訳ないのですが、今回の追記分のテストは1ヶ月以上前にやっていたことで、他の細かい条件がはっきりとは分からなくなってしまいました。さっさとブログに書けば良かった…(笑))。
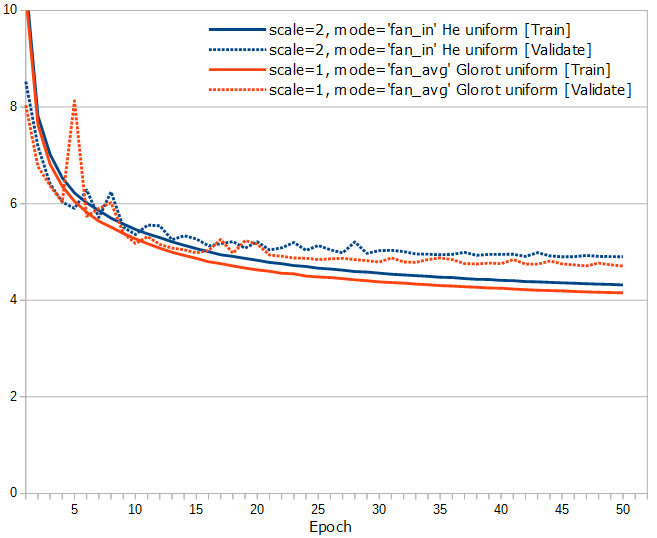
なんだか、あまり小さくない差があるように見えます。
glorot_uniformはVarianceScaling(scale=1., mode=’fan_avg’, distribution=’uniform’)と等価なんですが、次に、このscaleをいろいろな数値に変えた時の、1エポック目のTrain Lossをグラフにしてみました。
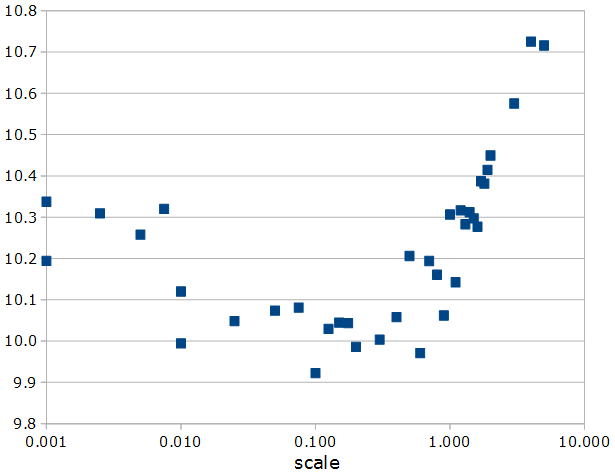
0.1ぐらいが一番良さそうで、Glorot uniformの1とそれなりに差があるように見えます。まあこれは、まだ1エポック目ですし、そしてValidate LossではなくTrain Lossですので、あまり真に受けてもいけないと思うのですが、「畳み込み層の初期値はなんでも良いわけではない」のは、間違いなさそうです。意外とこんな所に宝物が隠れていることが少なくないのかも…
[追記 2018/2/11]
続きの記事があります。
Keras/TensorFlowでDNNな囲碁の評価関数を作ってみる その2
https://www.perfectsky.net/blog/?p=380