前回の記事でも少し書きましたが、COSUMIでKataGoを使ってみようと思います。
囲碁ブラウザゲーム COSUMI
https://www.cosumi.net/
とりあえず19路盤の互先の対局でレベル8まで作ってみました。こちらがテストページ。今までの(と置き碁)はレベル1相当です。19路盤の互先以外は今までのと違いはありません。
https://www.cosumi.net/play-test20220703.html (正式にリリースしたので削除しました)
問題なく動くようであれば、正式にリリースします。重大な問題が発生したら、永久的に止める可能性も今はまだありますが、たぶん大丈夫かな? ぜひ一度遊んでみてください。注意点として、上のテストページからリプレイに行ってその後盤面クリックしても、元のテストページには戻りませんので、そこはご注意ください。また、予告なく削除されたりなんなりもします。
今回の19路盤のレベル設定は、レベルがひとつ違うもの同士での自己対戦の勝率が80%になるように調整しています。このあたりの話を書きだすとかなり長くなるので詳細は省きますが、おそらくですが、レベルのひとつ違いの差が9路盤などと比較して大きく感じられるのではと予想しています。でももう、この「自己対戦の勝率が80%」で今後もいきます。それなりにしっかりとした考えあってのことなので、変更することはまずありません。それにしても、この強さの設定はいつもながら本当に難しいですね… あちらを立てるとこちらが立たずで、どうにも収拾がつきません。今しばらくは微調整が続くと思います。あと、その方が打っていて楽しいのではと思うので、「どのように強さを変えているのか」もあえて今回はここに書かないでいようと思います。と言っても、もちろん特別なことは何もしていません。
今後の予定もここに書いておきます。まず、今回のテストが問題ないようであれば、19路盤よりも小さな15路盤、13路盤、11路盤、9路盤でも同じくレベル8ぐらいまでできるようにしたいと思います。それから、これも前回の記事に少し書きましたが、8路盤までの棋譜を日本語で添削するNNを今作っているので、それも使えるようにしたいと思います。で、それができたら、今ある9路盤までの悪手指摘の機能は、少なくとも日本語ページでは完全に削除するつもりです。その代りに、サーバ代との兼ね合いになりますが、9路盤以上ではKataGoに添削してもらえるかもしれません。ちなみに、この2つの添削機能は、COSUMIで打たれた棋譜に限らないようにするつもりです。以上の内、どれから実装するかは、現時点では未定です。これが全部できたら、私の中でCOSUMIはおしまい…
[追記 2022/7/9]
13路盤以下は、今でもそれなりに強いレベルで対局できるので、あまり急ぐ必要もないのですが、15路盤に関しては19路盤と同じ状況なので、最初のリリース時に、19路盤だけでなく15路盤でもレベル選択できるようにしたいと思います。現在、大急ぎで準備していますが、19路盤も今一度設定を詰め直したいので、正式なリリースまで早くても後2週間は掛かりそうです。
[追記 2022/7/21]
テストページで15路盤の互先でもレベル選択できるようにしました。15路盤は、「レベルがひとつ違うもの同士での自己対戦の勝率が78%」でいきます。19路盤も全て調整し直して、こちらはレベル9もいけそうですが、もういいですよね? 大きな問題が無ければ、このテストページの内容で3日後ぐらいに正式にリリースします。
レベル調整の作業は、どうしても待ち時間が大きくなるのですが、ここ最近はそれに合わせた生活リズムになっていましたし、時間が経ってしまうと勘所が頭から抜けてしまうので、次の作業としては、引き続き9路盤、11路盤、13路盤もレベル8ぐらいまでにしてしまおうと思います。そしてその次に、今ある悪手指摘の機能を、19路盤まですべて対応させる形でKataGoに置き換えたいと思います。ここまでいろいろやってきた感じでは、KataGoはかなり安定してますね。たまによく分からないおかしなことが起こっても、よくよく調べると、私かGNU Goが悪いことがほとんどでした。そして、やはりとても軽いです! なのでこれもできると思います。そして一番最後に、8路盤以下はそれを私の作った日本語で添削する機能に置き換えて、それで完成かなというのが今の予定です。あと書き忘れていたのですが、置き碁に関してはレベル選択も含め今後も一切変更加える予定はありません。
テストページで打ってくれる人が現時点までほとんどいませんでしたので、とりあえず今からCOSUMIで宣伝してきます。
[追記 2022/7/24]
正式にリリースしました。今回は、かなり大がかりなアップデートですし、エラーが出ない不具合が発生する可能性も高いので、まだかなり心配なんですが、とりあえず今のところは大丈夫でしょうか? ちなみに今現時点で、正式リリース後、19路盤レベル8の作り碁になった対局は、COSUMIの807勝13敗です。ユーザが投了しているケースも相当多いと思われます。
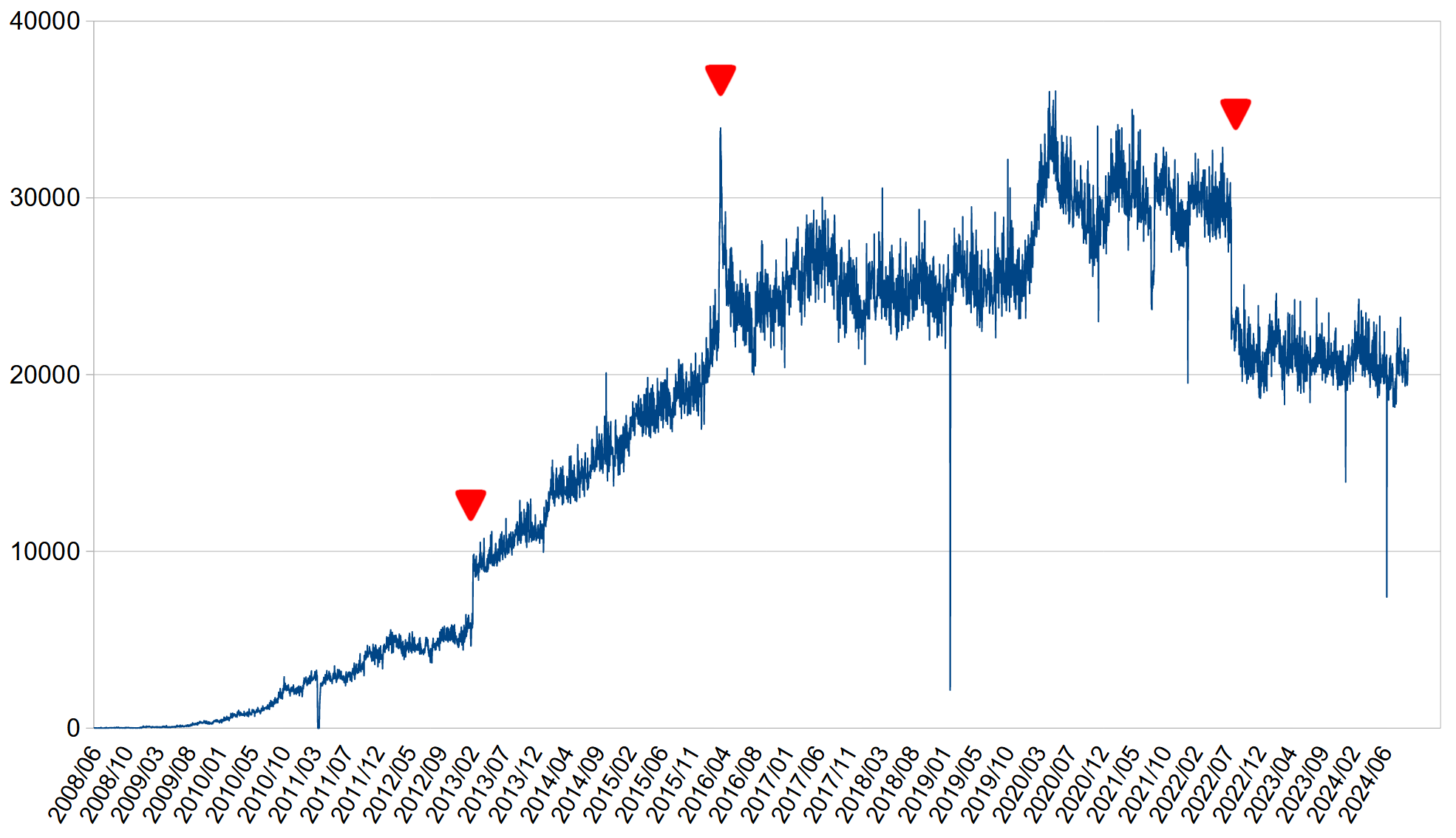
KataGo用の本番サーバは、当初、メインメモリが16GBのg5g.2xlargeで考えていたのですが、ちょっとお値段が気になってしまい、8GBのxlargeにしてしまいました。裏で何か作業する時に気をつかわされるのがいやですが、足りてるといえば足りてますので、何かあったらまたその時考えます。と思っていたら、CPUもボトルネックになりかねないことにちょうど今、気がついて、少し驚きました。でも、まあ大丈夫なはず。KataGo動かすというのに、メインメモリやCPUの心配ばかりして、GPUは安心っていうのもすごい話です…
で、g5gということでCPUがARMなんですが、ネットで調べてもKataGoを動かしている話はほとんど出てきませんが、特に何も問題なく使えています。Ubuntu 22.04、nvidia driver 515、CUDA 11.7、KataGo 1.11.0という最新(?)の組み合わせで、NVIDIAやKataGoのドキュメントどおりの手順でいけます。書かれていないことでやったのは、KataGoをビルドする時に、cmakeに-DCMAKE_CUDA_COMPILER=/usr/local/cuda-11.7/bin/nvccとオプションを付けたことぐらい。引っ掛かりポイントは特にありませんでした。そして、それでとても安定しています。他のクラウドサービスのことは、私はぜんぜん詳しくありませんが、g5g.xlargeはオレゴンで0.42USD/時間とお安いので、同じようなことをするのには、まあ良いのではないでしょうか? 今回いろいろ作業していて強く思ったのは、KataGoの動作環境はできるだけ多くの人で共有したほうがいいってことですね。日本棋院とかそういうことやらないんですかね? てかやってるのかな?
[追記 2022/7/26]
現時点で、正式リリース後、19路盤レベル8の作り碁になった対局はCOSUMIの3191勝39敗、レベル7は165勝6敗、レベル6は169勝6敗。今後、ガチな方々が遊んでくれるようになったとしても、強さはもう十分ですね。
KataGo用のサーバを追加した代わりに1台サーバを止めたのですが、結果、KataGo用のサーバ以外のリソースがぎりぎりになってしまいました。事前にユーザの行動が正確に読めなかったので仕方ない部分もあるのですが、正直、全く問題ないだろうと予測していました。AWSのSavings Plansの関係もあり、向こう1か月はこのままの構成で行かせていただきたいのですが、ちょっと無理かもしれません…
[追記 2022/7/28]
どこまでいっても正確な言葉の定義や数字を示しようがないのですが、いろいろ調べてみた感じ、19路盤レベル8でユーザが投了している対局は、作り碁になった対局の7倍ほどあるとみてよさそうです。この数字は、私の予想よりもかなり大きいのですが、投了するようなユーザは、投了で対局を早く終わらせる分、1人あたりの対局数が多いのかもしれません。加えて、これは最初から分かっていたことですが、ユーザが勝った対局も、結構な割合でユーザが人間ではなくコンピュータです(今回はあるのかどうか調べていませんが、COSUMI vs COSUMIとかやる人は昔からちょくちょくいます。ちなみに、私もテスト中に何回もやりました。AutoGo便利!)。となると、人間ユーザの勝率はもう0.1%ぐらいしかないことに… 確かに、レベル8はそれなりに強いのでしょう。しかし、それ以上に思うのは、COSUMIには本当に強い人は全然いないんだなあということです。もともとCOSUMIが弱かったのだから、当然でしかたのないことではあるのですが、これからはそういった方々にも価値を提供できるようになりたいですね。ぜひ一度、名のある方にレベル8をバサバサと叩き切ってもらいたいところです。
後、対局リプレイページにSGFをクリップボードにコピーするボタン用意しておきましたので、便利にお使いください。
[追記 2022/8/27]
9路盤、11路盤、13路盤でもレベル8まで強さを選択できるようにしました。ただ、本当に申し訳ないのですが、いろいろな事情があり、強さの最終的な微調整は、15路盤と19路盤の時とは違って、ユーザとの対局結果を確認しながらでやらせていただきます。ものすごく雑なことをしますが、総合的にそれが一番良さそうに思いました。今一番心配しているのは9路盤ですね。約1日分のデータから判断する限り何とかなってそうでもありますが、レベル8はかなりぎりぎりのようです。できれば残したいのですが…
それから、すべてのレベル、すべての碁盤サイズで、サーバの負荷が高い時に対局が開始できなくなるのを止めました。「9路盤のレベル6とレベル4はできるけどレベル5はできない」みたいなのは、ユーザも混乱するばかりですし、私も気持ち悪いのでそういうことにしました。サーバの負荷を見積もるにあたっていろいろ考慮しなければいけないことがあるのですが、これも約1日分のデータを見る限り、現在のサーバ構成で酷い状態になることは無さそうです。もし危なそうだったら、もうお金で解決してしまう予定です。
次は、KataGoに棋譜を分析させる機能を実装していきたいと思います。
[追記 2022/8/30]
9路盤レベル6~8をレベル0.2相当分ぐらい、11路盤レベル5~8をレベル0.3相当分ぐらい、13路盤レベル5~8をレベル0.4相当分ぐらい、弱くしました。一回これで様子を見てみます。
[追記 2022/9/14]
棋力を調整するために、ここ最近さまざまなデータを調べていたのですが、なんだかちょっと問題が多すぎますね… 詳しくはもうここに書きませんが、棋力を調整すると言ったって、「棋力」という言葉を気持ちよく定義しようがなく、どうにもやりようがありません。これは以前このブログでも書いたことがあるかもしれませんが、私は「COSUMIでは、新しいものを追加するのは自由にしていいけれど、すでにあるものはできるかぎり変更してはいけない」とかなり強く考えています。というのは、長い期間の中で、ユーザがCOSUMIを自身の棋力向上のベンチマークにしていることがとても多いからです。そういう考えがあったので、実際もう何年も、着手の変わる変更は基本的に行ってませんでしたし、また、そういった期間が長くなればなるほど、またさらになにか変更することが憚られるようになっていきました。今回、KataGoを使い始めていろいろ作業している時も、9~13路盤のレベル2以上も全部これに差し替えられたらなと何度も何度も思いましたが(ぱっと思いつくだけでもメリットは腐るほどあります)、それだけは絶対だめだと思い、真剣に検討することは一度も無かったんです。が、ここにきて、それがもうちょっと避けられない気がしてきました。
今回の話に関係する私がCOSUMIで実現したいことを、重要性の高い順に書き出していくとこんな感じです。
- 以前からあった9路盤のレベル1~レベル5、11路盤レベル1~レベル4、13路盤レベル1~レベル4、15路盤レベル1、19路盤レベル1の棋力を変えたくない
- 棋力は同じでも、できるだけきれいな手を打たせたい
- 同じ碁盤サイズの中で、レベルひとつ違いがすべて同じぐらいの棋力の違いに感じられるようにしたい
- すべての碁盤サイズで、数字の同じレベルが同じぐらいの棋力に感じられるようにしたい
- 以前からあった9路盤のレベル1~レベル5、11路盤レベル1~レベル4、13路盤レベル1~レベル4、15路盤レベル1、19路盤レベル1の棋風を変えたくない
- できるだけ説明が容易な基準で、それぞれのレベルの棋力を決定したい
- サーバの負荷を下げたい
いろいろ考慮した結果、これらをできるだけバランスよく実現するために、次のような変更を行うことにしました。
- 9路盤レベル2~レベル5、11路盤レベル2~レベル4、13路盤レベル2~レベル4を、それより上のレベルと同じようにKataGoベースに変更する
- それぞれの碁盤サイズのレベル2以上は自己対戦で同じ勝率になるように調整する
- レベル1とレベル2の間はまた別の勝率になるように調整する
ここまではもう決定事項です。自己対戦での勝率はもう少し微調整が必要だと思いますが、とりあえず、レベル2以上は9路盤で66%、11路盤で70%、13路盤で73%、15路盤で75%、19路盤で77%、レベル1とレベル2の間は、9路盤で71%、11路盤で75%、13路盤で78%、15路盤で80%、19路盤で82%で調整することにして、すでに変更しました。
変更前との比較を簡単に書いておきます。まず、すべての碁盤サイズでレベル1は何も変わっていません。9路盤レベル2~レベル5、11路盤レベル2~レベル4、13路盤レベル2~レベル4は、棋風が激変していると思います。棋力の方はあまり変わってないはずですが、ここをもう一度チェックする必要があります。9路盤レベル6~レベル8は、下の方は少し強くなり、上の方はあまり変わらず、11路盤レベル5~レベル8は、下の方は少し強くなり、上の方は少し弱く、13路盤レベル5~レベル8は、下の方はあまり変わらず、上の方は少し弱くといった感じ。15路盤と19路盤のレベル2~レベル8は、下の方はあまり変わりませんが、上に行くにつれ弱くなっていってレベル8は変更前のレベル7.2ぐらいです(そういうわけなのでレベル9以上も考えたほうが良いのですが、それはまた今度)。
今回の変更は新規のユーザにとっては間違いなく良い変更ですが、以前からのユーザにとって良いか悪いかは場合によるとしか言えないですね。それでも、もし今後長い期間遊んでもらえるのならば、やはり最終的には良い変更になる可能性が高いとも思います。結局のところ、これはCOSUMIをいつまで続けるのかが大きく関係していて、長く続けたいのであれば必要なアップデートに違いないのですが、私自身COSUMIを長く続けられるイメージがなかなか持てないんですよね… だから、こんなに躊躇してしまうのだと思います。
買ったばかりのc7gのSavings Plans、48万円ぐらいしたのですが、少し腐ったっぽい…(泣) なかなか上手くはいきませんね。なにか使い道はないかな?
[追記 2022/10/1]
5路盤~9路盤(レベル0)のみにあった悪手指摘の機能を廃止し、代わりに19路盤までに対応した新しい棋譜解析の機能をKataGoを利用して作ってみました。以前の悪手指摘機能とは比較にならないくらい精度が上がっていますし、結果的に悪手の指摘がたくさんできるようになっています。そして、悪手が無い時もその局面の良い手を表示するようにもしました。あと、目数による形勢の推移のグラフも用意しました。
今回の棋譜解析機能と以前の悪手指摘機能とのひとつ大きな違いとしては、悪手を指摘するタイミングが1手分早くなっていることがあります。COSUMIは基本的にまず「対局」があって、その後、その対局の手をどうこう言うってところから、一般的なその手の囲碁ソフトの「この局面ではここに打つのが良い/悪い」ではなく、「ひとつ前の局面でここに打ったのが良い/悪い」という1手後のタイミングで指摘が行われていました。理屈としては特におかしなことではなかったように思いますし、私自身、それを見づらいと思ったことは正直今までぜんぜん無かったのですが、今回、表示する情報量が増えたからでしょうか、盤面見ていると不思議な感じに頭がバグって、表示されていることの意味がどうにもこうにも取れなくなってしまったので、一般的なタイミングである1手前に早めました。ただ、そうなると今度は「良い手悪い手は分かったけど、実際に打った手はなんだっけ」ってどうしてもなりますので、次に打たれた石を半透明で表示するようにしています。乱暴な言い方をすると、0.2手分ぐらい今度は遅らせたイメージですね。このあたり、さんざんいろいろ試したのですが、まあこれで良いのではと今は考えています。
それから、ユーザの手番だけではなくCOSUMIの手番も解析しているのも大きな違いのひとつです。今までは、1手とばしで片側だけを見ていましたが、今回、形勢のグラフにも必要なこともあって黒白両側見るようになったので、COSUMIの手番でも良い手悪い手表示するようにしました。ユーザ側だけに表示を限定したいという要望は必ずあると思いますが、特別なUIを用意したくはありませんので、申し訳ありませんがこのまま使ってください。
最後にもうひとつ違いを挙げると、以前の悪手指摘機能は対局リプレイページに飛ぶだけで利用できましたが、サーバリソースが無駄に使われても困るので、今回からは基本的にワンクリック必要にしています。ただし、今現在はまだそうはなっていないのですが、8路盤以下に関しては自動で有効になるようにしようと思っています。というのは、8路盤以下は今までも自動だったからいうことがまずひとつと、あと、今私が作っている8路盤までの棋譜を日本語で添削するNNは、クライアントサイドで動かす予定で、だとしたら必ず自動で有効になるようにしますので、その時ともつながりがいいかなと思うからです。それから、サーバ負荷がまだちょっと正確には読めないので、現在は初手から最大100手までしか解析しませんが、これはおそらく300手までいけると思います。現在、データを取っているところなので、しばらくお待ちください。最終的には、サーバ負荷に応じて、多少の制限はするかもしれません。
それから、これも忘れずに書いておきたいのですが、今回の棋譜解析機能は、COSUMIで打たれた棋譜に限らず使えます。これとかこれとかから、適当にご利用ください。
対局も棋譜解析も、大量のパラメータを手で調整しなければいけませんので、しばらくは微調整が続きますが、KataGoを利用したもろもろの実装は、一応これにてひとまずおしまいです。この死ぬほど強くて、死ぬほど速くて、死ぬほど便利で、死ぬほど安定した神プロダクトを作ってくれたlightvectorぱいせんとゆかいな仲間たちに、心から感謝申し上げます。GNU Goをブラウザで動かしたいと思って始め、Fuegoで大きくなったCOSUMIですが、KataGoですべての夢が叶いました。今現在、KataGoは1日あたり約270万手打ってくれています。
[追記 2022/10/3]
8路盤以下でかつ総手数が100手以下の対局は、棋譜解析機能が自動で有効になるようにしました。また、解析するのが初手から最大100手までだったのを、最大200手に伸ばしました。これでもまだ余裕があるようなら、できるだけ早い段階で300手にします。今の感じだと、たぶん全く問題ないでしょう。それにしても、これだけの処理がg5g.xlargeで足りてしまうのは本当にやばいですね。ついCOSUMIを始めた頃のことと比べてしまうのですが、ハードもソフトも本当に性能向上したんですねえ… 今、囲碁を始めようとしている人が、ちょっと羨ましかったりしてしまいます。
[追記 2022/10/6]
初手から最大300手まで解析するように変更しました。
[追記 2023/2/4]
まだリソースにぜんぜん余裕があったので、15路盤以下でかつ総手数が250手以下の対局まで、棋譜解析機能が自動で有効になるようにしました。また、初手から最大500手まで解析するようにもしました。
それから、今現在使用している「レベル2以上は9路盤で66%、11路盤で70%、13路盤で73%、15路盤で75%、19路盤で77%、レベル1とレベル2の間は、9路盤で71%、11路盤で75%、13路盤で78%、15路盤で80%、19路盤で82%」という自己対戦での勝率は、もうこの数字で固定することにします。いろいろ考えたのですが、まあいいかげんなのではと思います。少し調べてみたところ、KataGoの新しいb18c384nbt-uecっていうモデルはかなり良さそうなので、もうしばらく時間をおいて少し様子を見たうえで、その新しいモデルの使用とこまごまとした修正を入れたものを、COSUMIの最後のバージョンとしたいと思います。そして、その時に19路盤はレベル9も追加すると思います。
去年の春ごろは「もうすぐできるかな?」なんて思っていた日本語で添削する機能は、ちょっと手が止まってしまいました… でも、これもできるだけ早く一回形にしたいと思います。